
لقد قرأت مؤخرًا عن طرق أكثر حداثة لتحليل
المصفوفة. يعتبر تحليل القيمة المفردة طريقة شائعة ، ولكن هناك المزيد. نزلت على الأرنب كله. بعد بضع خطوات من "الاطلاع على المراجع
الواردة فيه" ، وجدت شيئًا يبرر قضاء الوقت في هذا الأمر. ورقة ممتازة بعنوان "تحليل مصفوفة CUR لتحليل البيانات المحسنة". يصف هذا المنشور كيفية تحديد المتغيرات الأكثر أهمية من البيانات
بطريقة غير خاضعة للرقابة. يعني عدم الإشراف هنا عدم وجود متغير مستهدف في
الاعتبار.
محتويات
تحلل مصفوفة CUR
يوفر تحلل مصفوفة CUR بديلاً
للطرق الأكثر شيوعًا مثل SVD
أو PCA . لماذا تحتاج إلى بديل؟ لأن PCA
(على سبيل المثال) يوفر
لك بعض العوامل الكامنة. لكن هذه العوامل ليست مفيدة للغاية أو ذات مغزى
بأي طريقة استقرائية واضحة. إذا كنت تريد القصة وراء PCA ،
فأنت بحاجة إلى نشرها من الداخل ، عادةً من خلال النظر في تحميلات العامل واختراع
طريقة لتفسيرها. بعيدًا عن العامل الأول ، يمكن أن يكون الأمر
صعبًا للغاية ويعتمد على الكارما.
ورقة I الرجوع هنا تقترح خوارزمية للحصول على للتفسير انخفاض تقريب رتبة. يعتمد اقتراحهم على التقاط "تأثير"
متغير / عمود معين ، وهو ما جذب انتباهي: طريقة لقياس أهمية متغير معين (لعدم وجود
كلمة أفضل) ؛ عمود معين في مصفوفة البيانات الخاصة بك ،
بطريقة غير خاضعة للرقابة.
تقرأ المعادلة (3) في الورقة (الرابط أدناه)
أين  هي درجة الرافعة الإحصائية المعيارية لعمود معين
هي درجة الرافعة الإحصائية المعيارية لعمود معين  وهي ببساطة المتجهات الفردية الصحيحة من SVD لمصفوفة البيانات الأصلية.
وهي ببساطة المتجهات الفردية الصحيحة من SVD لمصفوفة البيانات الأصلية.
ما معنى درجات الرافعة المالية؟
سؤال جيد. سعر النفط هو أحد المتغيرات في المصفوفة التي تقود مؤشر أسعار المستهلك. من الناحية الاقتصادية ، يعد هذا المتغير
(العمود) مهمًا جدًا لفهم بيانات مؤشر أسعار المستهلك (المصفوفة). ألن يكون من الجيد أن يكون لدينا بعض الإجراءات
الإحصائية للتعرف على تلك الأعمدة المهمة؟ يبني PCA
مجموعات خطية تشرح
التباين في البيانات ، ولكن يصعب تفسيرها. فقط أخبرني ما هي المتغيرات المهمة ، وليس أي مجموعة خطية مهمة. أن تكون قادرًا على توضيح المتغيرات
"المهمة" بدون أي هدف هو اقتراح جذاب تمامًا ، على ما أعتقد.
دعنا نفحص أعلى 94 سهم من الأسهم القيادية في
السوق ونرى ما إذا كان بإمكاننا تحديد الأسماء الفردية الأكثر صلة بكل حركة
البيانات ، باستخدام طريقة درجات الرافعة المالية الإحصائية هذه. ها هي النتائج (الكود أدناه). اتضح أن هذه هي أهم الأسماء بمعنى أنها تقود
معظم الحركة في البيانات:
[1] "BBY" "QCOM" "OKE" "KR" "WBA"
[1] "BBY" "QCOM" "OKE" "KR" "WBA"
ما الذي يجعل لمتغير خاص؟
بالطبع ، السؤال المثير للحكة هو ما الذي يميز
تلك الأسماء التي تم اختيارها؟ هل لأن لديهم أكبر انحراف معياري (SD من الآن فصاعدًا)؟ حتى يمارسوا شد كبير على المصفوفة الشاملة؟ دعونا تحقق:
توزيع الانحراف المعياري لجميع المخزونات في البيانات
الخمسة أشرطة الرأسية الرمادية هي تلك الأسماء الخمسة. نرى أن SD الخاص بهم يقع بالفعل فوق المتوسط ، ولكننا نرى أيضًا أن هناك أسماء أخرى ذات SD أعلى لم يتم تمييزها على أنها مهمة بشكل خاص بناءً على درجة الرافعة الإحصائية الخاصة بهم.
ماذا عن الارتباط المتبادل؟ كل اسم له علاقة مع البقية. يوضح الشكل أدناه ، في المتوسط ، مدى ارتباط كل اسم بكل الأسماء
المتبقية: الأشرطة الرأسية الخمسة الرمادية هي تلك الأسماء
الخمسة. نرى أن لديهم ارتباطًا أقل في المتوسط ببقية
الأسماء.
لذلك لكي يتم وضع علامة على الاسم على أنه مهم
في البيانات ، يجب أن يكون له دقة قياسية عالية مع الحفاظ على
"استقلاليته" قدر الإمكان. إذا كان للاسم تباين كبير ، ولكنه يرتبط أيضًا
ارتباطًا وثيقًا بالباقي ، فإنه ليس مهمًا بشكل خاص ، بينما إذا كان الاسم مستقلاً
تمامًا ، ولكنه ليس مؤثرًا جدًا على الحركة الكلية في البيانات (انخفاض SD) ،
فهو أيضًا لا تستحق اهتماما خاصا.
باختصار
توضح الطريقة الإحصائية الموضحة في هذا المنشور
كيفية التحقق من "تأثير" أو "أهمية" متغير معين في سياق
بيانات المصفوفة. تبين أن المؤثر ، يعني بديهيًا ، ذو تقلبات
عالية إلى حد ما ، ولكنه مستقل تمامًا عن الباقي - وبالتالي يستحق المزيد من
الاهتمام. استخدم هذا الإجراء العددي لفحص المتغيرات
الفردية ، بدلاً من تركيبة خطية كما هو الحال مع PCA ، تعتبر مهمة للحركة الإجمالية في البيانات. الميزة الرئيسية ، ربما الوحيدة ، هي من حيث القابلية للتفسير. من الأسهل بكثير توصيل المتغيرات المهمة بدلاً
من توصيل أي مجموعة خطية من المتغير مهمة.
شرح فهم التباين في PCA
يعد تحليل المكون الرئيسي
(PCA) أحد
أقدم التقنيات متعددة المتغيرات. ومع ذلك ، فإنها لم تنج فحسب ، بل إنها الطريقة
الأكثر شيوعًا لتقليل أبعاد البيانات متعددة المتغيرات ، مع تطبيقات لا حصر لها في
جميع العلوم تقريبًا.
رياضيا ، يتم تنفيذ
PCA عبر
وظائف الجبر الخطي تسمى التحلل الذاتي أو تحلل القيمة المفرد. حتى الآن لا أحد يهتم بكيفية
حسابها. يعد تطبيق PCA سهلاً مثل الفطيرة في الوقت
الحاضر - مثل العديد من الإجراءات العددية الأخرى حقًا ، من واجهات السحب والإفلات
إلى prcompR أو from sklearn.decomposition import PCAفي Python. لذا فإن تنفيذ
PCA ليس
هو المشكلة ، ولكن مع ذلك يلزم بعض اليقظة لفهم الناتج.
هذا المنشور يدور حول فهم
مفهوم التباين الموضح . مع خطر الظهور بمظهر متعالي
، أظن أن العديد من خبراء الإحصاء / علماء البيانات من الجيل الجديد يرددون ببساطة
ما يُشار إليه غالبًا على الإنترنت: "يشرح المكون الرئيسي الأول الجزء الأكبر
من الحركة في البيانات الإجمالية" دون أي فهم عميق. ماذا يعني "يشرح الجزء
الأكبر من الحركة في البيانات الإجمالية" بالضبط ، في الواقع؟
من أجل شرح مفهوم "شرح التباين" بشكل صحيح ، نحتاج إلى بعض البيانات. سنستخدم مقياسًا صغيرًا جدًا حتى نتمكن من تصور ذلك لاحقًا بسهولة. يتم الآن سحب السعر من yahoo للمؤشرات الثلاثة التالية: SPY (S&P) و TLT (السندات الأمريكية طويلة الأجل) و QQQ (NASDAQ). لنلقِ نظرة على مصفوفة التغاير لسلسلة العوائد اليومية:
من أجل شرح مفهوم "شرح التباين" بشكل صحيح ، نحتاج إلى بعض البيانات. سنستخدم مقياسًا صغيرًا جدًا حتى نتمكن من تصور ذلك لاحقًا بسهولة. يتم الآن سحب السعر من yahoo للمؤشرات الثلاثة التالية: SPY (S&P) و TLT (السندات الأمريكية طويلة الأجل) و QQQ (NASDAQ). لنلقِ نظرة على مصفوفة التغاير لسلسلة العوائد اليومية:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
library(quantmod)
library(magrittr)
library(xtable)
#
citation("quantmod"); citation("magrittr") ;
citation("xtable")
k <- 10 # how many years back?
end <- format(Sys.Date(),"%Y-%m-%d")
start <-format(Sys.Date() -
(k*365),"%Y-%m-%d")
symetf = c('TLT', 'SPY', 'QQQ')
l <- length(symetf)
w0 <- NULL
for (i in 1:l){
dat0 =
getSymbols(symetf[i], src="yahoo", from=start, to=end,
auto.assign
= F,
warnings =
FALSE,symbol.lookup = F)
w1 <-
dailyReturn(dat0)
w0 <-
cbind(w0, w1)
}
dat <- as.matrix(w0)*100 # percentage
timee <- as.Date(rownames(dat))
colnames(dat) <- symetf
print(xtable( cov(dat), digits=2), type=
"html")
|
|||||
|
TLT
|
الجاسوس
|
QQQ
|
||||
|
TLT
|
0.77
|
-0.40
|
-0.39
|
|||
|
الجاسوس
|
-0.40
|
0.90
|
0.96
|
|||
|
QQQ
|
-0.39
|
0.96
|
1.20
|
|||
كما هو متوقع ، فإن
SPY و
QQQ لهما
تغاير مرتفع بينما TLT ، كونها سندات ، في المتوسط تتحرك سلبًا مع الاثنين الآخرين.
نقوم الآن بتطبيق
PCA مرة
واحدة على البيانات التي ترتبط ارتباطًا إيجابيًا للغاية ، ومرة واحدة على
البيانات التي لا ترتبط ارتباطًا إيجابيًا للغاية حتى نتمكن من مقارنة النتائج
لاحقًا. نطبق PCA على مصفوفة تستثني
TLT: c("SPY", "QQQ")(أطلق عليها PCA_high_correlation) و PCA على مصفوفة لا تحتوي إلا على
عمودي TLT و SPY (أطلق عليها PCA_low_correlation):
|
1
2
3
4
5
|
PCA_high_correlation <- dat[, c("SPY",
"QQQ")] %>% prcomp(scale= T)
PCA_high_correlation %>% summary %>%
xtable(digits=2) %>% print(type= "html")
PCA_low_correlation <- dat[, c("SPY",
"TLT")] %>% prcomp(scale= T)
PCA_low_correlation %>% summary %>%
xtable(digits=2) %>% print(type= "html")
|
PCA_high_correlation:
|
جهاز الكمبيوتر 1
|
PC2
|
|
|
الانحراف المعياري
|
1.42
|
0.28
|
|
نسبة التباين
|
0.96
|
0.04
|
|
النسبة التراكمية
|
0.96
|
1.00
|
PCA_low_correlation :
|
جهاز الكمبيوتر 1
|
PC2
|
|
|
الانحراف المعياري
|
1.11
|
0.65
|
|
نسبة التباين
|
0.74
|
0.26
|
|
النسبة التراكمية
|
0.74
|
1.00
|
أظن أن الملخص التفصيلي يساهم
في عدم فهم الطلاب الجامعيين. في الأساس ، يجب إعطاء الصف الأول فقط حتى يضطر
أي مستخدم إلى اشتقاق الباقي إذا احتاج إلى ذلك.
الخطوة الأولى لفهم الصف
الثاني هي حسابه. يعطي الصف الأول الانحراف المعياري للمكونات
الأساسية. قم بتربيع ذلك للحصول على التباين. هذا Proportion of Varianceهو مقدار التباين الإجمالي
الذي يتم شرحه بواسطة كل من أجهزة الكمبيوتر فيما يتعلق بالكل (المجموع). في حالتنا النظر في PCA_high_correlationالجدول:  . لاحظ أننا قمنا الآن بالربط
بين تباين المكونات الرئيسية ومقدار التباين الموضح في الجزء الأكبر من البيانات. لماذا هذا الارتباط هناك؟
. لاحظ أننا قمنا الآن بالربط
بين تباين المكونات الرئيسية ومقدار التباين الموضح في الجزء الأكبر من البيانات. لماذا هذا الارتباط هناك؟
المتوسط عبارة عن تركيبة
خطية من المتغيرات الأصلية ، حيث يحصل كل متغير  . يعد الكمبيوتر أيضًا مجموعة
خطية ولكن بدلاً من كل من المتغيرات الأصلية ، يتم الحصول علىالوزن ، يحصل على وزن آخر
يأتي من الإجراء العددي PCA. نسمي تلك الأوزان "التحميلات" أو
"الدوران". باستخدام هذه التحميلات يمكننا
"التراجع" عن المتغيرات الأصلية. إنه ليس تعيينًا واحدًا
لواحد (لذلك ليس الأرقام الدقيقة للمتغيرات الأصلية) ، ولكن باستخدام جميع أجهزة
الكمبيوتر ، يجب أن نستعيد الأرقام التي هي ارتباط كامل (الارتباط = 1) مع
المتغيرات الأصلية *. ولكن ماذا سيكون الارتباط إذا حاولنا
"التراجع" ليس باستخدام جميع أجهزة الكمبيوتر ولكن فقط مجموعة فرعية؟ هذا هو بالضبط المكان الذي
يلعب فيه تنوع أجهزة الكمبيوتر. إذا لم يكن الأمر واضحًا تمامًا في هذه المرحلة
، فانتقل إلى النهاية. سيصبح أكثر وضوحا كما ترى الأرقام.
. يعد الكمبيوتر أيضًا مجموعة
خطية ولكن بدلاً من كل من المتغيرات الأصلية ، يتم الحصول علىالوزن ، يحصل على وزن آخر
يأتي من الإجراء العددي PCA. نسمي تلك الأوزان "التحميلات" أو
"الدوران". باستخدام هذه التحميلات يمكننا
"التراجع" عن المتغيرات الأصلية. إنه ليس تعيينًا واحدًا
لواحد (لذلك ليس الأرقام الدقيقة للمتغيرات الأصلية) ، ولكن باستخدام جميع أجهزة
الكمبيوتر ، يجب أن نستعيد الأرقام التي هي ارتباط كامل (الارتباط = 1) مع
المتغيرات الأصلية *. ولكن ماذا سيكون الارتباط إذا حاولنا
"التراجع" ليس باستخدام جميع أجهزة الكمبيوتر ولكن فقط مجموعة فرعية؟ هذا هو بالضبط المكان الذي
يلعب فيه تنوع أجهزة الكمبيوتر. إذا لم يكن الأمر واضحًا تمامًا في هذه المرحلة
، فانتقل إلى النهاية. سيصبح أكثر وضوحا كما ترى الأرقام.
بالعودة إلى مثال
PCA ثنائي
المتغيرين. خذها إلى أقصى الحدود وتخيل أن تباين أجهزة
الكمبيوتر الثانية هو صفر. هذا يعني أنه عندما نريد "التراجع"
عن المتغيرات الأصلية ، فإن الكمبيوتر الشخصي الأول فقط هو المهم. فيما يلي مخطط لتوضيح حركة
جهازي الكمبيوتر في كل من PCA الذي قمنا به.
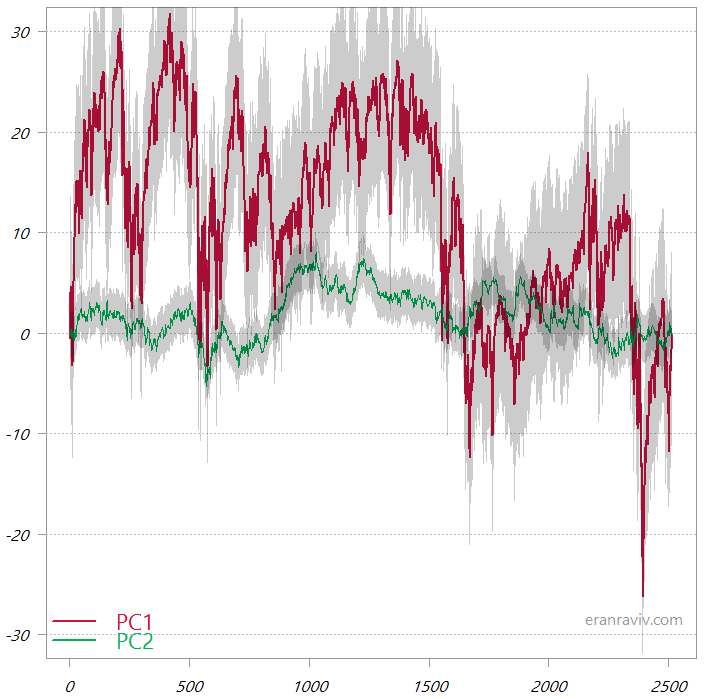
يمكنك أن ترى أن المكون الرئيسي الأول هو أكثر تنوعًا ، لذلك عندما "نتراجع" إلى مساحة المتغير الأصلية ، سيكون هذا الكمبيوتر الشخصي الأول الذي يخبرنا بشكل كامل تقريبًا بالحركة الإجمالية في مساحة البيانات الأصلية. على النقيض من ذلك ، ألق نظرة على جهازي الكمبيوتر من PCA_low_correlation:
أول جهازي كمبيوتر من PCA_low_correlation
هذه هي المبالغ
التراكمية للمكونين الرئيسيين. المنطقة المظللة هي انحراف معياري
واحد.
في هذا الرسم البياني ،
كما يتضح أيضًا من الجدول الثالث في هذا المنشور ، فإن تباين جهازي الكمبيوتر أكثر
قابلية للمقارنة. هذا يعني أنه الآن من أجل "التراجع" إلى مساحة
المتغير الأصلية ، سيعطي العامل الأول الكثير من المعلومات ، لكننا سنحتاج أيضًا
إلى العامل الثاني لإعادة التعيين الحقيقي إلى الفضاء المتغير الأصلي.
أتعلم؟ دعونا لا
نكون كسالى ونفعل ذلك. دعنا نتراجع
عن المتغيرات الأصلية من أجهزة الكمبيوتر ونتخيل مقدار ما يمكننا قوله باستخدام
المكون الأول فقط ومقدار ما يمكننا تحديده باستخدام كلا المكونين. طريقة التراجع عن المتغيرات الأصلية (مرة أخرى ، ليس تعيين
واحد لواحد ..) باستخدام مصفوفة التدوير:
Back out to
the original space
القيم "المسحوبة" على القيم الفعلية لـ PCA_high_correlation
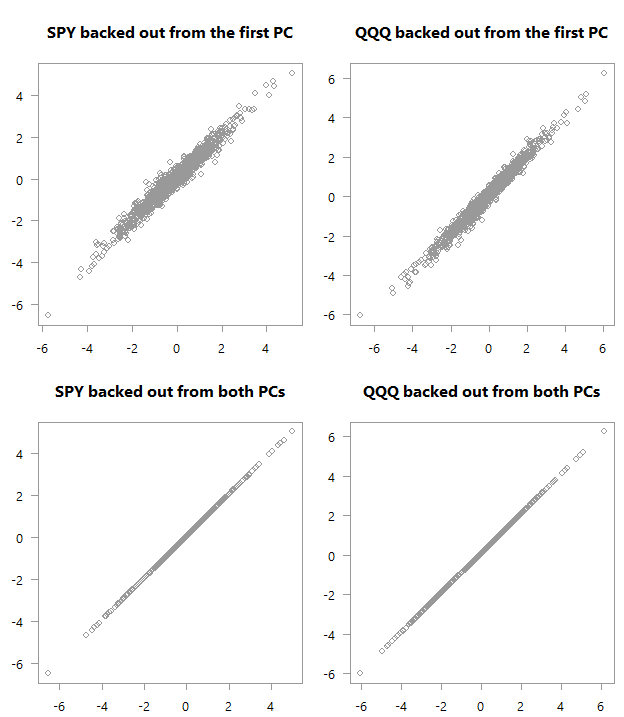
أعلى: مخطط مبعثر للمتغيرات الأصلية كما تم نسخها احتياطيًا من
الكمبيوتر الشخصي الأول فوق قيمها الفعلية. أسفل: بالطبع ،
إذا كنت تستخدم جميع أجهزة الكمبيوتر ، فستستعيد المساحة الأصلية.
القيم "المسحوبة" على القيم الفعلية لـ PCA_low_correlation
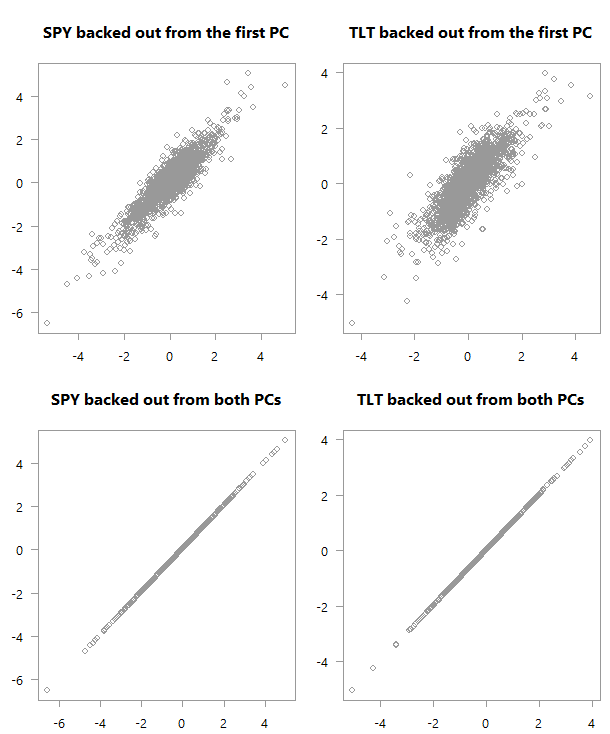
أعلى: مخطط
مبعثر للمتغيرات الأصلية كما تم نسخها احتياطيًا من الكمبيوتر الشخصي الأول فوق
قيمها الفعلية. أسفل: بالطبع ، إذا كنت تستخدم
جميع أجهزة الكمبيوتر ، فستستعيد المساحة الأصلية.
ضع في اعتبارك اللوحات الأربعة في كل من
المخططات أعلاه. شاهد كيف يوجد في الرسم البياني الأول ارتباط
أقوى بكثير بين ما حصلنا عليه باستخدام أول جهاز كمبيوتر فقط والقيم الفعلية في
البيانات. لا نحتاج تقريبًا إلى العامل الثاني من أجل
الحصول على تطابق تام من حيث الحركة في المساحة الأصلية (أتمنى هنا أن تكون سعيدًا
لأنك واصلت القراءة). مدهش جدا إذا كنت تفكر في ذلك. يمكنك أن ترى سبب قيمة أعمال PCA هذه ؛ لقد اختزلنا المتغيرين إلى واحد دون فقدان أي معلومات تقريبًا. الآن فكر في منحنى العائد. ترتبط هذه المعدلات الشهرية / السنوية ارتباطًا وثيقًا ، مما يعني
أننا لسنا بحاجة إلى العمل مع العديد من السلاسل ، ولكن مع سلسلة واحدة (أول
كمبيوتر شخصي) دون فقدان الكثير من المعلومات.
العودة إلى الرسوم البيانية لدينا. في الرسم البياني السفلي ، نشعر جيدًا بالبيانات
من جهاز الكمبيوتر الأول. لكنها ليست قوية مثل ما نحصل عليه في الحالة
الأولى (الرسم البياني العلوي). والسبب هو أن الارتباط المنخفض يجعل تلخيص
البيانات أكثر صعوبة إذا صح التعبير. نحتاج إلى المزيد من المكونات الرئيسية
لمساعدتنا على فهم الحركة
(co) في الفضاء المتغير
الأصلي.
الحواشي
* هذا لأن PCA
غالبًا ما يكون PCA مركزًا (نركز المتغيرات الأصلية ، أو نركز عليها
ونقياسها - وهو ما يشبه العمل مع مصفوفة الارتباط بدلاً من مصفوفة التغاير)
لطلب تحليل احصائي التواصل عبر الواتس اب اضغط هنا

ليست هناك تعليقات:
إرسال تعليق